Learn how AutoAI can automate data preparation, model development, feature engineering, and hyperparameter optimization
In recent years, data-driven decision making has become critical to the success of corporations. There are many benefits of using technology for data-driven practices including the optimization of production and manufacturing, reductions in customer attrition, reductions in data redundancy, increased profitability, and the creation of competitive advantage. So data science has become popular as organizations embrace data-driven decision-making approaches. Data scientists need a wide range of skills including mathematics and statistics, machine learning and artificial intelligence (AI), databases and cloud computing, and data visualization. However, it is difficult to recruit enough data scientists, particularly with sufficient domain knowledge, such as banking, healthcare, human resources, manufacturing, and telco, for the tasks to be performed and decisions to be made. And increasingly, data science is becoming a kind of literacy, in that an understanding of data science techniques is required for many job roles, including roles where the employees do not have strong coding skills.
o in parallel to the development of new tools to increase data scientist work efficiency, technical developments have emerged that focus on the creation of software to automate tasks within the data science workflow such as Google’s AutoML, H2O, DataRobot, and open source libraries like Auto-sklearn and TPOT. Many of these systems build on scikit-learn Python machine learning libraries. They are examples of AI for AI, in that AI technology is being used to build an AI solution. IBM® has produced state-of-the-art AI for AI technology and incorporated it into its product portfolio – in the form of AutoAI.
What is AutoAI?
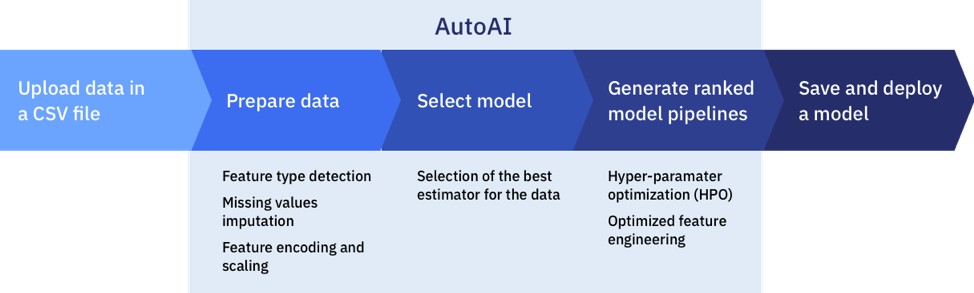
AutoAI automates data preparation, model development, feature engineering, and hyperparameter optimization. AutoAI AI lifecycle management is a great help when getting started and when exploring what questions to ask. It then supports subsequent experimentation, model modifications deployment, and governance steps. AutoAI comes as standard with IBM Cloud Pak for Data to be used and scaled across hybrid multicloud environments. AutoAI is also available on IBM Cloud through IBM Watson™ Studio.
AutoAI is an exciting example of AI for AI. The AutoAI tool automatically analyzes your data and generates candidate model pipelines that are customized for your predictive modeling problem. These model pipelines are created over time as AutoAI algorithms learn more about your data set and discover data transformations, estimator algorithms, and parameter settings that work best for your problem. Results are displayed on a leaderboard, showing the automatically generated model pipelines ranked according to your problem optimization objective, encouraging you to experiment further.
Better together: Ask better questions with AutoAI
Data science is frequently about asking better questions, for example, identifying the appropriate attributes that are predictors for an outcome through exploration. That means building many different models, selecting different features, and applying different hyperparameter optimizations. Options in AutoAI make it possible to explore better questions either by speeding up the AI process or by offering points of human engagement.
The entire AutoAI process can be automatically completed in minutes (depending on data volumes and other considerations) without human intervention, creating a baseline solution and making it suitable for beginners. However, domain experts can easily interact with AutoAI to incorporate their knowledge into the automated pipeline to improve the model produced and to customize to their local requirements.
Examples of optional points of human interaction where experts can manually specify their own preferences in the automated AutoAI process to incorporate their domain knowledge include:
- Data preparation – splitting data to train and test with subsets, filling in missing values
- Advanced data refinery – specifying a subset of data to save resources and time, joining multiple data sources
- Feature engineering – applying certain off-the-shelf feature transformations, creating new features from the interactions of multiple features
- Neural network search – adopting specific architecture from the latest scholarly publications
- AutoAI pipeline optimization – selecting certain off-the-shelf algorithms, or plugging in existing algorithms
- Hyperparameter optimization (HPO) – turning HPO on or off, or choosing to run HPO each time after an auto-feature-engineering step; defining the search space for certain hyperparameters
- One-click deployment – choosing the target deployment environment, on IBM Cloud or on other cloud infrastructures
- Explainability and debiasing – detecting and mitigating bias from data, algorithms, or training with the help of AI Fairness 360
- AI lifecycle management – monitoring post-deployment performance in real time and improving model performance with reinforcement learning in one click
AutoAI comes as standard with Cloud Pak for Data to be used and scaled across hybrid multi-cloud environments. There are a number of benefits for AutoAI, particularly in support of humans working to better understand and make predictions about their particular business or specialty. The benefits include:
- Building models faster because AutoAI prepares data, identifies features, performs optimizations, and generates models much faster than humans doing the work by themselves.
- Overcoming the skills gap, making it possible for industry domain experts who are new to data science to incorporate data science methods into their daily work.
- Uncovering more use cases because exploring models is quicker, giving more time for data scientists to experiment.
- Identifying key predictors that make a difference by using the auto-feature engineering option, which makes it simpler to extract predictions from a data set.
- Ranking and exploring models by comparing candidate pipelines to determine the best model for the particular task.
- Deploying models easily through AutoAI-generated pipelines. The deployed models can then be accessed and predictions made through REST APIs.
This technology is changing quickly, so stay tuned for further developments in the areas of transfer learning, business constraints, and more.
AutoAI comes as standard with IBM Cloud Pak for Data to be used and scaled across hybrid multicloud environments. AutoAI is also available on IBM Cloud through IBM Watson™ Studio.